This is a collaborative space. In order to contribute, send an email to maximilien.chaumon@icm-institute.org
On any page, type the letter L on your keyboard to add a "Label" to the page, which will make search easier.
Organisational recommendations : subjects, scripts, where and how
- Former user (Deleted)
- Maximilien CHAUMON
Here we describe the recommended organization for your data folder. It will ease the execution of the generic scripts you find in the wiki. It will also simplify the backup of your analysis. You are free to change this organization if your data doesn't fit in our generic framework.
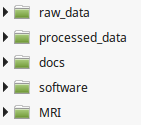
raw_data: the MEG center is about to adhere to the MEG-BIDS specifications.
processed_data: it is recommended to separate raw and processed data so as to avoid accidentally removing original files.
docs: could contain various important documents and analysis records.
software: it is recommended to keep a separate version of the software you use for your analysis for each project.
MRI: the CENIR center is about to adhere to the BIDS specifications to store brain imaging data.
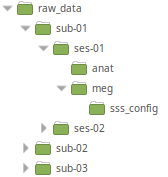
raw_data
This section follows the Brain Imaging Data Structure (BIDS) recommendations for MEG data.
This is the original article defining the standard: Niso et al. - 2018 - MEG-BIDS, the brain imaging data structure extende.pdf

BIDS validator
You can check that your folder structure is correctly formed, and that all necessary files are present with the bids-validator. Just visit this page and point to the study folder (raw_data in the example above).
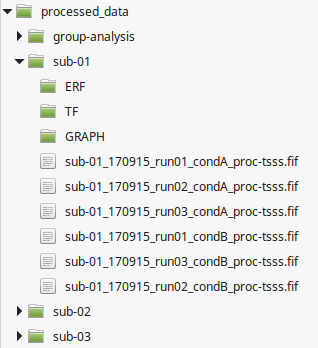
processed_data
Contains the results of all the processing applied to the raw data. Here the organization depends on the way you choose to analyze the data.
Keep this folder clean
Once your analysis pipeline is setup, we recommend to 1) remove all test files 2) keep all processing steps.
You can keep the 1 folder = 1 subject scheme for all the preprocessing steps (tsss, artefacts removal, sensor level analysis and fieldtrip processing).
You will likely end up doing a group analysis, it should be stored in the subfolder named group-analysis here.
Brainstorm does that for you
One advantage of using Brainstorm is that it does all of this file bookkeeping for you. Just create a BST_db folder instead of the processed_data folder for your Brainstorm database.
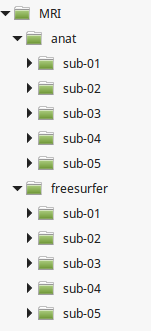
MRI (may soon need update to adhere to the BIDS specifications)
This folder should contain the 3D T1 for each subject. It will be used in the localization process. If you plan to use freesurfer, here are the recommended sub folders:
anat
Contains the original data (currently in nifty format) for each subject, one folder per subject S1 to SXX
freesurfer
Contains the freesurfer results for each subject, one folder per subject S1 to SXX
freesurfer_reconall
Contains 1) the freesurfer commands used to generate the results in the freesurfer folder , 2) the corresponding log file (check it if something went wrong during the processing).
docs
You may store various documents like:
- checklist (to be printed for each participant)
- template consent form (to be printed for each participant)
- all the results
- illustrations
- abstracts
- manuscripts...
software
scripts
Contains the scripts (shell, python, matlab etc.) used during your analysis
toolboxes (fieldtrip, brainstorm...)
Contains the version(s) of the toolboxes used during your analysis.
Keep original versions
Beware not to update your software without consideration. It is not rare to see scripts fail after updating toolboxes to new versions.
Ideally, use a versioning software like git to keep track of modifications made to this software folder (scripts and toolboxes).